
AlphaGo, a computer Go program developed by Google DeepMind, might have beaten 18-time world champion Lee Sedol at a Go match, but Lee used a mere 20 Watts to operate, less power than a lightbulb. In contrast, AlphaGo used 1,920 CPUs and 280 GPUs, which is 50,000 times as much power as what Lee’s brain uses.
Deep learning networks are hitting bottlenecks when they scale to more complex tasks and bigger models. Many of these models require enormous amounts of power, raising sustainability issues and creating environmental threats. Training a deep learning model can produce 626,000 pounds of carbon dioxide, which is equivalent to the lifetime emissions of five cars.
We recently announced a technology demonstration that indicated that our brain-inspired sparse network algorithms are 50 times faster than dense networks and use significantly less power. In this blog post, we will walk through some visualizations of our results that ultimately validate how sparsity can enable massive energy savings and lower costs.
Before we walk through the visualizations, we need to understand the concept of sparsity.
The highly sparse brain
How is the brain so efficient? There are many reasons, but at its foundation is the notion of sparsity. The brain stores and processes information as sparse representations. Suppose you are looking at a painting; as your eyes move along the canvas, you see different colors and shapes, which activate some of the neurons in your visual cortex. But if we could look inside your brain as you view this painting, we’d see that at any given time, most of the neurons are inactive. The same goes for your auditory system. In every sensory region, there is a sparse pattern of activity that represents a perception of the world in any point in time. You can think of the active neurons as 1’s and inactive neurons as 0’s.
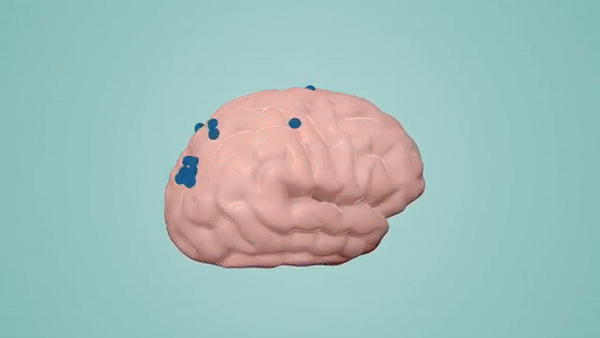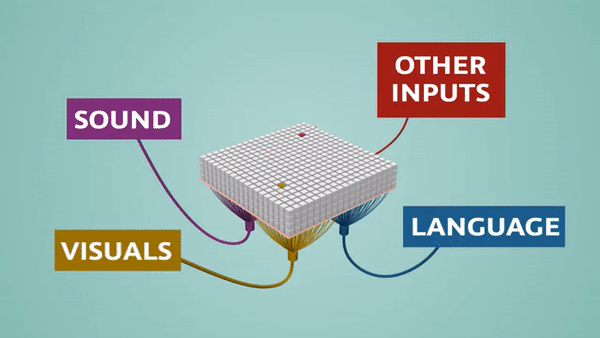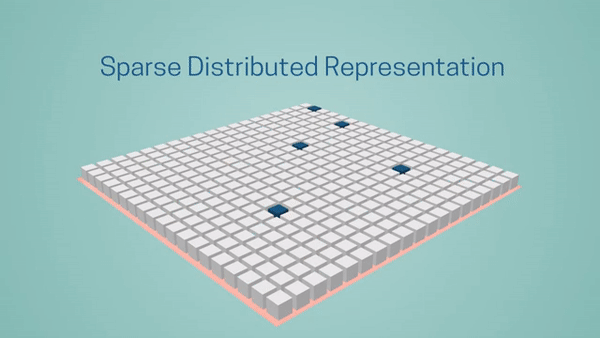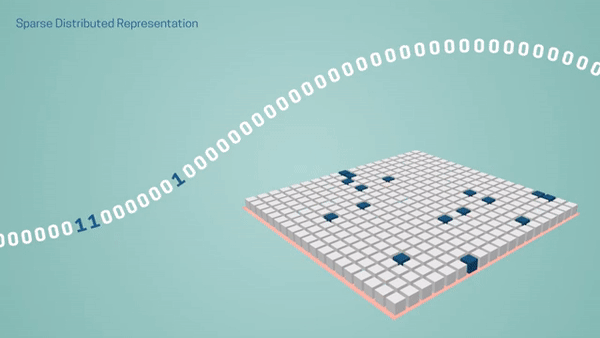
Traditional deep learning networks use dense representations, which means a much higher number of active neurons, requiring many more computations. For example, when performing a common operation like matrix multiplication, where you multiply each row by each column, a dense network will require a considerable number of computations. In a sparse network, however, because most of the values are 0’s, a large percentage of computations can be eliminated.
Our Technology Demonstration: 50x performance acceleration in deep learning networks
For our technology demonstration, we wanted to validate the efficiency of sparse networks by applying our brain-derived sparse algorithms to machine learning, and compare our sparse and dense networks on an inference task.
We chose the Google Speech Commands (GSC) dataset, which consists of 65,000 one-second long utterances of keywords spoken by thousands of individuals. The task is to recognize the word being spoken from the audio signal. Then, we implemented sparse and dense networks on three off-the-shelf Xilinx FPGAs. The sparse networks are highly sparse, similar to the neocortex, and the dense networks are standard convolutional networks. We chose an FPGA as the hardware platform to run the performance tests because of the flexibility it provides in handling sparse data efficiently. Please refer to our technical whitepaper for more details.

The graph above shows the throughput, measured as the number of words processed per second, for a dense and sparse network on a Xilinx Alveo U250 board, the most powerful of the three FPGAs we selected. We can see that the sparse configuration is 50 times faster than the dense configuration.
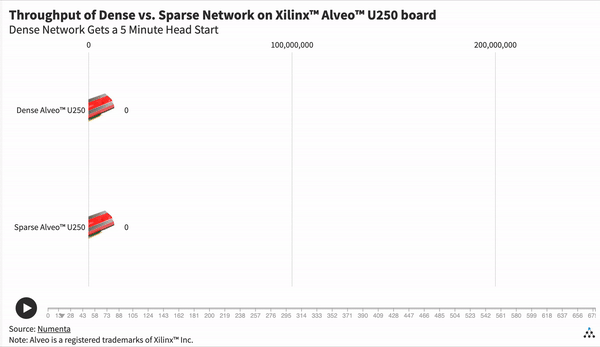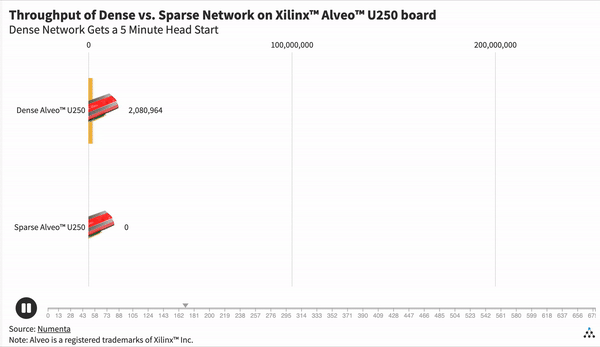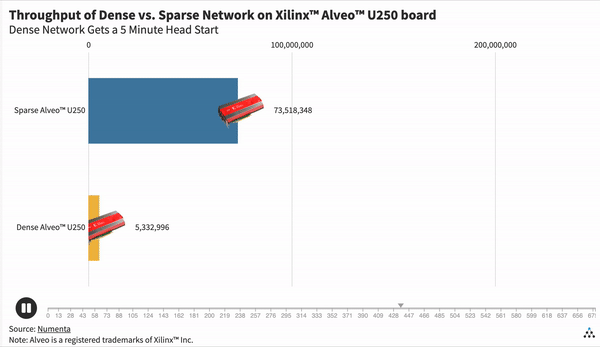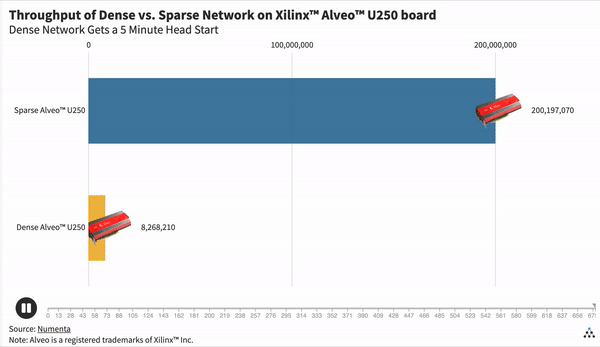
Here we give the dense network a 5 minute head start. Once we start the sparse network, it only takes 5 seconds to overtake the dense network.
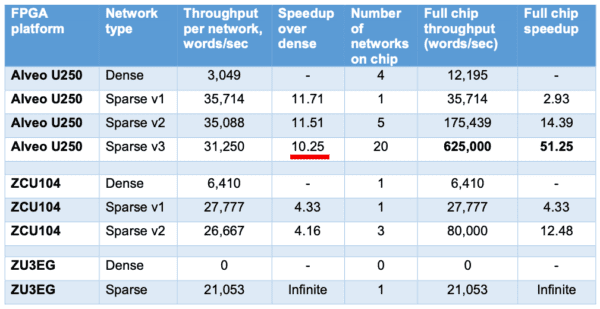
This substantial speed-up is due to both the efficiency of a single sparse network and the overall throughput. As we see in the table above, a single network running on a sparse configuration is 10x faster than that of a dense configuration. Since each sparse network is much more compact, we can fit at least 20 sparse networks on the U250 board compared to 4 dense networks. This gives us the potential to pack more networks in a chip, reducing the need to scale up and resulting in massive energy savings and lower computational costs.
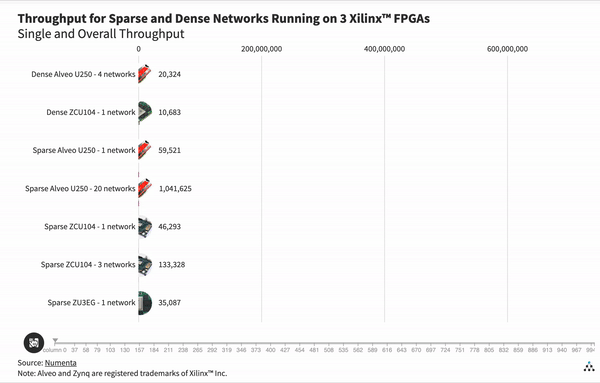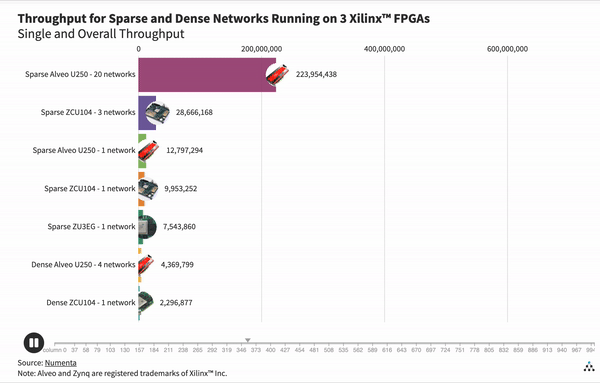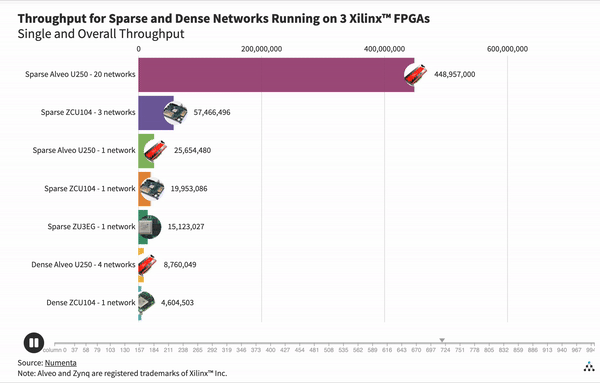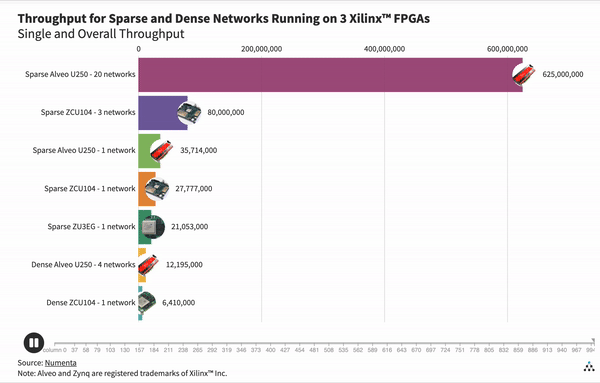
Interestingly, the dense GSC network cannot fit on the small Zynq UltraScale+ ZU3EG chip. Since the sparse network is significantly smaller, we can fit a single network on that chip. As we can see in the graph above, our results indicate that the throughput of that single sparse network on the small chip is 1.7 times faster than the total throughput of four dense networks running on the powerful Alveo U250. These results show the flexibility of sparse networks and open up potential for ultra small, energy efficient platforms that are able to run deep learning based applications without compromise.

Lastly, we looked at power consumption, which is becoming increasingly important in assessing deep learning system efficiency. In the graph above, we compare our most efficient dense configuration to our most efficient sparse configuration. The most efficient dense configuration in terms of power usage is the ZCU104, but the 20 network sparse configuration on the Alveo U250 is still 26x more power efficient. It is worth noting that 20 sparse networks do not consume the whole board. We estimate that it is possible to pack another 5-10 sparse networks on the Alveo U250, leading to even higher throughput while keeping power consumption low.
Towards Sustainable AI
Some excitement over AI’s recent progress has shifted to alarm. As models scale up, their power consumption and costs also increase. Turning to the brain for insights has become not just an alternative, but a necessity, to advance the field. As we continue to implement more of the Thousand Brains Theory in algorithms, we are confident that we can lead machine intelligence to a more sustainable and efficient pathway.
We have several additional resources for people who want to learn more:
- Press Release: Numenta Demonstrates 50x Speed Improvements on Deep Learning Networks Using Brain-Derived Algorithms
- White Paper: Technology Validation: Sparsity Enables 50x Performance Acceleration in Deep Learning Networks
- Visualizations Video: Technology Demonstration Visualizations
- The Case for Sparsity in Neural Networks, Part 1: Pruning
- The Case For Sparsity in Neural Networks, Part 2: Dynamic Sparsity
- How Can We Be So Dense? The Benefits of Using Highly Sparse Representations
- Sparse Distributed Representations – (BAMI Chapter 3)
- Sparse Distributed Representations: Our Brain’s Data Structure
- HTM Forum – a great resource for further questions and discussion on this technology demonstration. Numenta researchers and engineers are active on the forum.
Note: Numenta, Google, Xilinx, Alveo and Zynq are trademarks of their respective owners