
As powerful as today’s AI technology is, scaling it for real-world inference remains a significant challenge. We recently announced version 2.0 of our AI platform – the Numenta Platform for Intelligent Computing (NuPIC™), which is designed to help you navigate the complicated AI landscape and deploy your AI applications in a private, scalable, and cost-efficient way.
One of the primary hurdles is the high costs associated with deployment, as large AI models like GPT-4 and LLAMA3 require significant computational resources to maintain. Moreover, businesses relying on online SaaS platforms often have limited control over their data, raising security and privacy concerns. Cloud-based generative AI models are also prone to hallucinations and can be unreliable. For instance, businesses lack control over compute resources which can affect throughput or latency for critical tasks; cloud-based models can also be unexpectedly discontinued or removed. With new state-of-the-art models emerging daily, it’s hard to decide which AI solutions are truly viable and beneficial for a business’s specific needs.
Build and Deploy Generative AI Applications with NuPIC 2.0
NuPIC is a software AI platform that enables the efficient deployment of large language models (LLMs) on CPUs. By mapping our neuroscience-based AI techniques to modern CPU architectures, NuPIC delivers significant performance enhancements and incredible flexibility.
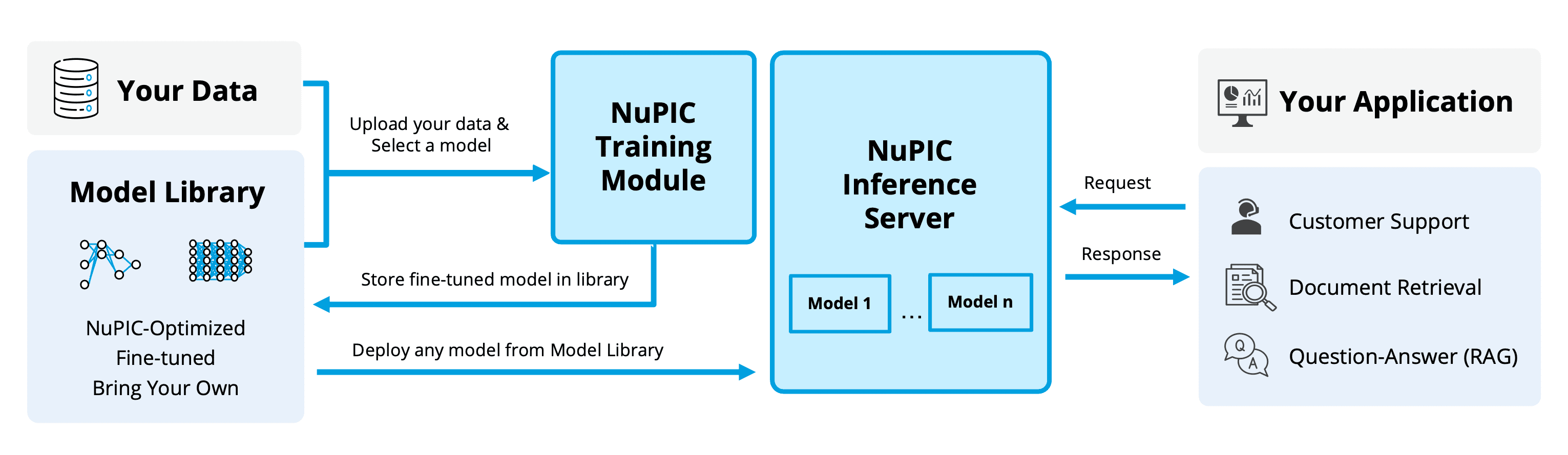
Here are some key highlights of NuPIC 2.0:
- Unmatched GPT inference throughput on CPUs: At the heart of NuPIC 2.0 is our optimized inference server that runs LLMs efficiently on CPUs. It supports a range of models, including our suite of optimized LLMs. Our GPT models are optimized for both throughput and latency, without compromising accuracy. For instance, our NuPIC-optimized GPT 7B on an Intel 5th Gen Xeon CPU is roughly 3x faster than an off-the-shelf LLAMA2 7B on an NVIDIA A100. Moreover, the combination of CPU flexibility and NuPIC models enables businesses to run multiple instances and types of models on the same server, allowing them to scale their applications regardless of demand.
- Bring your own model: NuPIC is not limited to pre-optimized models. We recognize that businesses have unique needs and may already have models that work well for them. Hence, NuPIC offers the flexibility to upload and deploy your custom models with ease. We currently support a curated list of models that can be deployed within NuPIC’s ecosystem with no changes to model performance, and in most cases, running your own model in NuPIC is faster than running it in PyTorch on a CPU. NuPIC’s model library also includes popular open-source models such as LLAMA3 8B as an out-of-the-box solution. We are actively expanding our platform to accommodate a broader array of model architectures, ensuring that our customers can integrate the latest state-of-the-art AI advancements into their applications.
- GPT fine-tuning support: As an option for specific tasks or domains, you can fine-tune our optimized GPT models or your own models using your domain-specific data. Fine-tuning can significantly improve the accuracy and relevancy of the model’s outputs. We offer sample code for fine-tuning, making it accessible even for users without extensive AI/ML expertise. Fine-tuning on NuPIC is 100% private, meaning Numenta has no visibility to any of your data and models. Simply upload your data, configure the parameters, and let our platform securely handle the rest.
Why Choose NuPIC?
With a focus on flexibility and real-world applications, NuPIC makes it easy for businesses to choose and deploy the right model for the right task.
- 100% private and secure AI deployments: NuPIC is fully containerized, meaning that data, models and applications are 100% within your infrastructure and under your control. Deploying NuPIC on-premise ensures that your sensitive data remains private and secure, eliminating the risks associated with cloud-based services. No data ever gets sent to Numenta servers.
- Easy to use, AI-ready solutions: NuPIC comes with AI-ready industry solutions such as document retrieval via retrieval augmented generation (RAG), dialogue summarization in customer support and language generation in video game development. We also provide recommendations on the optimal base model and configurations required for different use cases. Our comprehensive documentation and example codes allow you to quickly deploy your LLMs on NuPIC in your existing CPU-based infrastructure without needing any AI expertise.
- Minimize total cost of ownership (TCO) through CPU-based approach: Running NuPIC on CPUs is the ideal, most cost-effective and sustainable solution for scaling large AI workloads. The platform delivers high-performance inference with minimal computational overhead on existing hardware infrastructure, allowing you to deploy AI applications at a much lower cost compared to traditional GPU-based systems. This ensures that you get the most out of your AI investments while keeping total costs down.
If you’re interested in learning why NuPIC makes CPUs the ideal solution for deploying LLMs, read this blog here.
NuPIC in Action: Streamlining Customer Support with RAG
NuPIC’s RAG pipeline leverages retrieval-based models (i.e. embedding models) and generative models to provide accurate and contextually relevant answers. It is a powerful tool that turns raw data into actionable insights and is especially useful in customer support systems and enterprises that have mountains of unused data. Additionally, RAG addresses the hallucinations from large generative models, making the system outputs much more reliable.
You can use NuPIC’s generative models to summarize extensive, error-prone customer support dialogues. You can then use NuPIC’s embedding models to generate embeddings from these summaries, store the embeddings in a searchable database and build a question-answering system. When a support agent engages with a customer, the model compares the customer query with the stored summaries, retrieves the most relevant ones, and provides real-time recommendations to the agents.

To simplify the implementation process, we provide easy-to-use example code that ties these components together. This enables you to quickly experiment with your own data and seamlessly implement RAG on NuPIC in your operations.
Conclusion
As the demand for generative AI applications continues to grow, the need for scalable, secure and efficient solutions becomes increasingly critical. Don’t let the challenges of deploying large AI models hold you back. Unlock the full potential of your generative AI applications and stay ahead of the curve by leveraging NuPIC today.
Interested in NuPIC but not sure where to start? Request a free consultation here.