
In recent months, Numenta has been highlighting the synergy between our AI Platform and Intel’s latest 4th generation (Sapphire Rapids) processor with its new AMX (Advanced Matrix eXtensions) support. In concert with Intel, we have demonstrated over two-orders of magnitude improvement in inference throughput for BERT-Large models [here, here, and here].
Since that time, we have been busy applying our neuroscience-based optimizations to other LLMs (large language models). Most recently, we have focused on GPT (Generative Pretrained Transformer) models. This class of LLMs has been attracting significant interest, predominately because of Open AI’s ChatGPT product. ChatGPT has galvanized the world’s attention, with almost daily coverage in the mainstream media in recent months, as highlighted in Figure 1.
ChatGPT and the broader family of GPT models are generative AI models, that given an input, produce new content. Most problem types can be mapped to this paradigm: language translation, chat, content generation, text summarization and question answering, to name but a few. While generative AI solutions have been around for a while, the fluency and sophistication of the results created by the latest models such as ChatGPT is game-changing. As a result, companies are racing to understand where and how they can leverage this technology. However, while they deliver SOTA results, GPT models are extremely computationally expensive.

Why are GPT models so expensive?
There is a general awareness of the costs associated with training ChatGPT and other GPT models, but the inference costs are potentially less well understood. And these costs can be significant – significantly higher than the costs associated with BERT-style models. The reasons for these increased costs are three-fold, as illustrated in Figure 2.
- These models are large. While most companies won’t need to deploy large 100B+ GPT models unless they are solving a general search problem, there is significant interest in models ranging from 500M to 10B parameters; representing a size increase over BERT-large from 1.6X to 33X. This increase in size leads directly to increased inference costs.
- In contrast to BERT models, these GPT models are autoregressive and generate the response token by token. This necessitates running the model multiple times to generate a single result. While the exact processing strategy varies from model to model, each word is typically represented by one or more tokens, with a 100-word response requiring that the model be run over 100 times! For companies used to working with BERT (a stack of encoders), where the model is typically run once, many are unprepared for this additional compute multiplier.
- With the newer GPT models, an increasingly large span of input text can be considered during the generation of each new token, increasing the contextual awareness of the model. Newer GPT models support between 4K and 32K token contexts (in contrast, BERT analyzed a max of 512 tokens), further increasing the compute cost associated with predicting each output token.
As a result, moving to GPT models for inference significantly increases the computational requirements and associated costs. For many customers this is extremely problematic . The promise of generative AI is great, and most companies have numerous high-value use-cases that could benefit from leveraging this transformational technology. However, the cost (and energy footprint) associated with these models represents a major obstacle to adoption.
How can companies control the costs?
Companies can control the costs of generative AI in several important ways. Firstly, there needs to be a discussion of whether an expensive generative AI solution is required. Many problems can be solved using BERT-large or similar models. Is deploying a GPT model necessary? Are the accuracy improvements delivered by large GPT models meaningful to the business problem being solved?
Secondly, in situations that require generative AI, don’t automatically assume a 100B+ parameter GPT model is required to solve every problem. The complexity and scope of the problem, along with the accuracy requirements, all influence the size of model. By defining the problem that needs to be solved, gathering good, clean data for fine-tuning, leveraging pretrained models, and ensuring modern training recipes, many customers are finding that significantly smaller models can be leveraged effectively. In many instances, model capacity is not the limiting factor for achieving higher quality, but rather inadequate training signal resulting from insufficient quality data: in situations where the desired accuracy is not obtained, customers are finding that larger LLMs can be used to help cost-effectively create improved training data and labels.
Dramatically reduce inference costs with Numenta
Numenta’s neuroscience-based technology can radically reduce the costs associated with generative AI. Deploying optimized GPT models from Numenta’s model zoo on our AI platform can deliver significant reductions in inference costs, while preserving model accuracy. For instance, running Numenta’s AI platform on Intel’s latest Xeon server processors can improve GPT inference performance by over 60X, across a broad range of model sizes. Figure 3 illustrates the inference throughput achieved for a 6-billion parameter GPT-j-6B model. In this benchmark, we are targeting short conversational exchanges, with a batch size of 1, and comparing the total inference throughput achievable using both a 3rd Generation Xeon processor and an NVIDIA A100, both running without Numenta’s technology, with a 4th Generation Xeon processor leveraging Numenta’s technology.
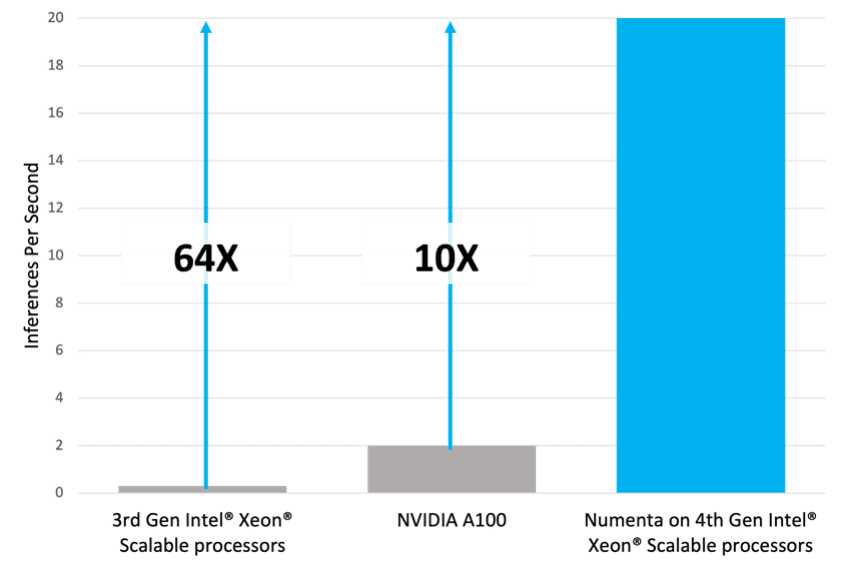
Not only does Numenta’s technology provide significant acceleration on CPUs, outperforming A100 GPUs by 10X enables businesses to choose to use CPUs instead of GPUs for inference of large GPT models. Performance improvements of this scale can be game-changing, and while the above results focus on raw throughput, these efficiency improvements can be leveraged to address a variety of pain points. The most obvious benefits include improved scale and efficiency (more requests per system) or reduced costs (fewer systems needed to support the current load), but there are two other interesting opportunities:
- Latency reduction: inference latency can be reduced on CPUs by dedicating a larger number of cores to servicing each inference operation. For any set number of cores per inference operation, Numenta’s AI platform delivers a significantly lower inference latency. As a result, it can be cost-effective to deliver latencies that are over 10X lower than achievable with vanilla models using the same number of cores. This can allow large GPT models to be cost-effectively used in applications with real-time constraints.
- Accuracy improvements: in many instances, latency or cost considerations may limit the size of model that can be practically deployed. With Numenta’s technology, we shift the model cost-accuracy curve, enabling significantly larger models to be run as fast and cheaply as small vanilla models. For example, if cost and latency considerations dictate a model no larger than 1B parameters, Numenta’s AI platform can run a 10B+ parameter model just as efficiently. This allows customers to achieve business-altering accuracy improvements by using a larger model while meeting their existing cost, latency, and throughput constraints.
In conclusion, generative AI is an exciting and transformative technology which will continue to gain adoption across a wide range of use cases. However, the associated compute costs are significant. Using Numenta’s AI platform, which is deployed directly into customer infrastructure, these costs can be reduced by up to 60X, allowing enterprises of all sizes to fully exploit the game-changing technology.
Get Started Today
If you’re interested in accelerating GPT models on CPUs, we’d love to work with you. Whether your problem requires a smaller Bert model or a multi-billion parameter GTP model, our AI platform can help you create the most optimized, highly performant, cost-effective model, tuned to your use case. Contact us by visiting Numenta.com/gpt and get started today.