
From releasing a book to publishing scientific papers, 2021 was quite a busy year for Numenta. If you haven’t had a chance to catch up on what we’ve been up to, I’ve rounded up our top content of the past year.
Complementary Sparsity Enables Highly Efficient Sparse-Sparse Networks
No matter where you look in the neocortex, the activity of neurons is sparse, meaning only a small fraction of the brain’s neurons are active at any given moment and individual neurons are only interconnected with a small fraction of the total neurons in the brain. Limiting the number of neurons that are active simultaneously is referred to as activation sparsity, and limiting the interconnectedness of neurons is referred to as weight sparsity.
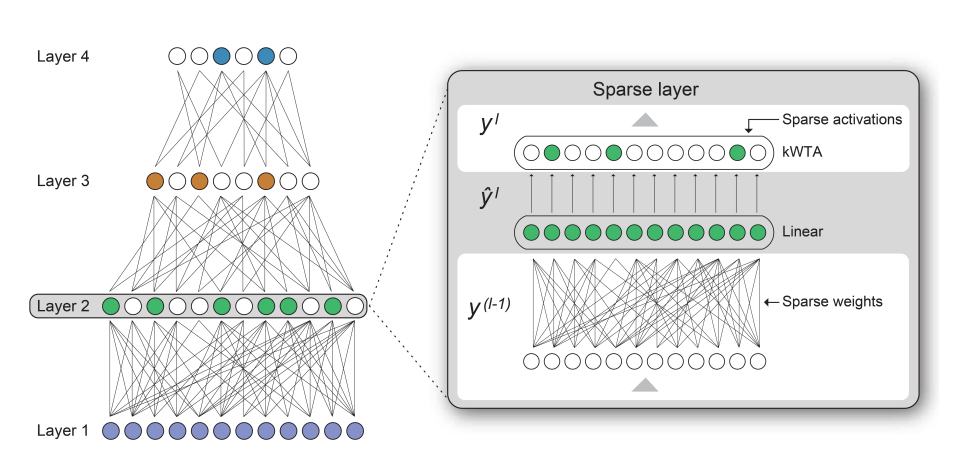
In 2021, we made significant progress in introducing these two key aspects of brain sparsity into machine learning algorithms and existing hardware systems.
- Our results show that sparse networks can perform 100 times faster than non-sparse networks on an inference task while maintaining accuracy.
- We took a step towards improving network efficiency and driving down energy usage by achieving a 10x parameter reduction in Google AI’s BERT model with no loss of accuracy.
- Rather than creating hardware to support unstructured sparse networks, we propose an alternative that inverts the sparsity problem by structuring sparse matrices such that they’re almost indistinguishable from dense matrices. We call this novel approach Complementary Sparsity.
We showed that combining these two types of sparsity can yield multiplicative benefits as sparsity avoids many unnecessary operations altogether. By combining Complementary Sparsity with our recent work on sparse transformer models, we have a path to unlock the full potential of sparsity and further drive down energy usage while getting a proportionate speedup and achieving competitive accuracy. Ultimately, we think sparsity provides a clear path to how we can scale AI systems, making them more robust and efficient.
Avoiding Catastrophe with Active Dendrites
The most fundamental component in neuroscience and deep learning is the neuron itself. Biological neurons can give us insight into our ability to continuously learn new things without forgetting information from the past.
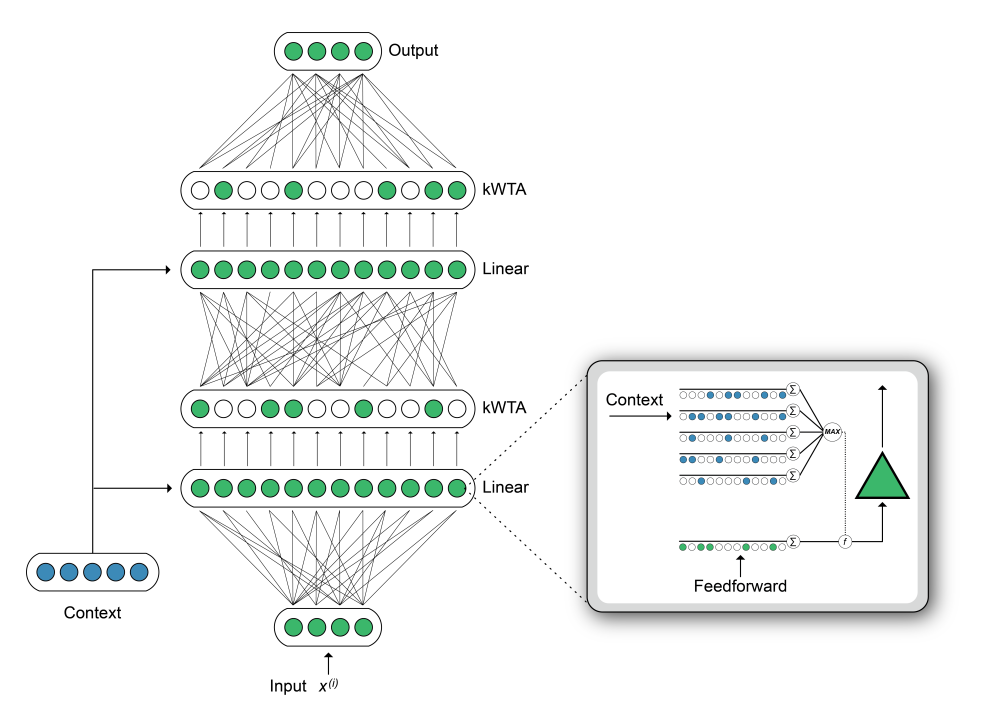
Last year, we proposed a new deep learning architecture with augmented standard artificial neurons with properties of active dendrites and sparse activations. Using dendritic modulation together with a k-Winner-Take-All mechanism, we found that subsets of neurons minimally interfere with each other during learning and significantly improve the network’s ability to do multiple tasks at once.
Our results for both multi-task RL and continual learning suggest that:
- Our network with dendritic context integration may represent a general-purpose architecture for avoiding interference and forgetting in complex settings.
- In multi-task settings, a biological neuron’s activity cannot be approximated by a neural network with more parameters or more layers. Instead, the neuron’s properties may play a critical role in handling complex dynamic scenarios.
Sharing Ideas
In addition to our research on sparsity and active dendrites, our team explored other essential aspects of the neocortex and how we can apply them to machine learning algorithms. We continued to explore empirical and theoretical neuroscience research by reviewing papers and inviting experts in academia and industry to share their insights.

One notable speaker was Richard Sutton, often considered the father of modern computational reinforcement learning, who talked about the increasing role of sensorimotor experience in AI and proposed a minimal architecture for an intelligent agent that is entirely grounded in experience. We also looked at the role of grid cells and how they act as an inspiration for machine learning architectures.
We have been seeing a number of exciting and innovative advances in brain-inspired machine learning. We look forward to having fruitful interactions with even more researchers and authors as we proceed down the path of advancing machine intelligence with neuroscience.
A Thousand Brains
In early 2021, our co-founder Jeff Hawkins published his book A Thousand Brains: A New Theory of Intelligence. A Thousand Brains builds on the discoveries Jeff made with the Numenta team that led to the first unified theory of how the brain works. Jeff explores what it means to be intelligent and how understanding the brain impacts the future of neuroscience, AI and even humanity.

Since its release, A Thousand Brains has been named one of Bill Gates’ Top 5 Books of 2021. As he explains in his review, “If you’re interested in learning more about what it might take to create a true AI, this book offers a fascinating theory.”
The release of the book kept Jeff busy with his virtual book tour. Here are a few of our favorite articles and appearances:
- Lex Fridman Podcast
- Machine Learning Street Talk Podcast
- MIT Technology Review – “We’ll never have true AI without first understanding the brain”
- ZDNet – “A love letter to the brain: in his new book on AI, Jeff Hawkins is enamored of thought”
Numenta News Digest: Staying Up-To-Date with the World of Biologically-Inspired Intelligence
Since 2018, we have been putting together a short, curated list of AI/Neuroscience focused news, delivered straight to your inbox. Last year, we gave our News Digest a fresh look and feel. Besides sifting through the headlines to bring you the stories that we find interesting, we also included Numenta’s take and why we think they matter.
In addition to that, our Digest seeks to transform the hard-to-understand neuroscience and machine learning concepts into simple and digestible terms. You can view our latest issue and subscribe here.
Looking Forward in 2022
While we are pleased with the progress we made in 2021, we have more to do. In 2022, we look forward to sharing more progress, both on our continuing efforts to speed and scale existing AI systems with Complementary Sparsity, and on our long-term mission of enabling the creation of truly intelligent machines that can understand the world.
Be sure to subscribe to our Newsletter to stay up-to-date with company news and research updates.