
Human beings are remarkably robust at learning and retaining knowledge over time, despite the fact that the perceptual inputs we receive from the world are continuously changing. Unfortunately, the same cannot be said for artificial neural networks and this consequently restricts their use cases to settings where they’re only required to perform a single task.
In our new preprint titled “Going Beyond the Point Neuron: Active Dendrites and Sparse Representations for Continual Learning”, we investigated how to augment neural networks with properties of real neurons, specifically active dendrites and sparse representations. Inspired by neuroscience findings, we hypothesized these mechanisms will permit knowledge retention over time. We found that these additions significantly enhanced a network’s ability to learn sequentially, just as humans easily do.
What is continual learning, and why are neural networks bad at it?
Continual learning is the ability to learn new items or concepts sequentially without losing previously-acquired knowledge. Humans do this effortlessly and it’s critical to daily life: when we master a new skill while at school or work, we don’t forget how to use a smartphone, how to get home afterwards, or how to introduce ourselves to a new colleague—all of which we previously learned to do. Neural networks, on the other hand, struggle under such circumstances, and this phenomenon is known as catastrophic forgetting. (We also discussed continual learning and catastrophic forgetting in a previous blog post.) Neural networks can therefore only be deployed to do one specific thing, and even though they surpass human capabilities at certain tasks (e.g., playing Go), they are widely regarded as “Narrow AI”.
Forgetting in neural networks is a consequence of two aspects acting in unison. First, roughly half of the neurons “fire” for any given input that the network processes. Second, the backpropagation learning algorithm, which enables learning in neural networks, modifies the connections of all firing neurons. (This is a consequence of the mathematics of backpropagation.)
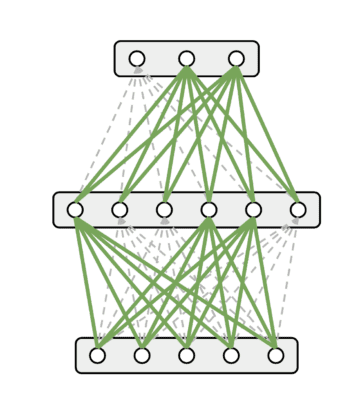
Putting these two aspects together, the implication is that learning to predict the output for a single input causes roughly half of all connections to change! (In the cartoon illustration below, that would be all the green connections.) The “knowledge” of a neural network exists solely in the connections between neurons, hence previously-acquired knowledge is rapidly erased as the network attempts to learn new things. This is a terrible outcome from a continual learning perspective since a large portion of the network is essentially changing all the time.
How active dendrites and sparsity enable continual learning
Since humans are great continual learners, we explored two underlying biological properties that bring about this ability. First, unlike in artificial neurons (in a neural network), most of the inputs received by a biological neuron cannot directly cause it to fire, however they can make the neuron more likely to fire, and the segments that receive these inputs are called active dendrites. To picture this, imagine a race with five sprinters at the starting line. Only one of them hears “Ready, set …”. She anticipates the race is about to start, and is primed to start running. Here, the effect of “Ready, set …” on the sole runner who heard this signal is equivalent to active dendrites priming a neuron to fire. In the following diagram, the green arrows correspond to feedforward input that directly causes a biological or artificial neuron to fire, while the blue arrows represent input received by active dendrites that can heighten the chance that the neuron fires.
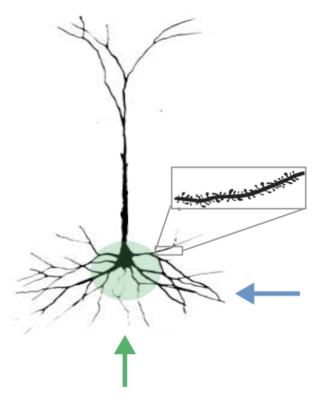
Second, sparse representations in the brain emerge as neural firing is highly sparse. Sparsity is a consequence of local inhibition, a property whereby if a neuron fires, other neighboring neurons are prevented from simultaneously firing, and this largely motivated past work on sparsity at Numenta. Relating this idea back to the sprinter analogy, once all runners hear “Go”, the sole sprinter who heard the preparatory signal jumps out way ahead of the other runners, who then give up and decide to wait for the next race. The effect of the other runners observing one that leaps out in front is an inhibitory effect.
What do active dendrites and sparse representations achieve? Active dendrites decide when a neuron is likely to fire (which may be at different times for each neuron), while sparsity ensures that only a small fraction of neurons are firing at any given time. Coupling these two factors together, we get different neural circuits, comprising mostly separate sets of neurons, that specialize in learning or performing different tasks. As learning in the brain is a sparse process itself, only the neurons in the active circuit see their connections to other neurons modified; all other neurons and their connections remain unchanged. This is quite a departure from the backpropagation algorithm updating approximately half of all connections in a neural network.
Does it work in silico?
We translated the aforementioned ideas into a software implementation. In our model, the artificial neuron was augmented with dendritic segments (i.e., additional connections), which received a different source of input than the feedforward connections and modulated the behavior of the neuron accordingly.
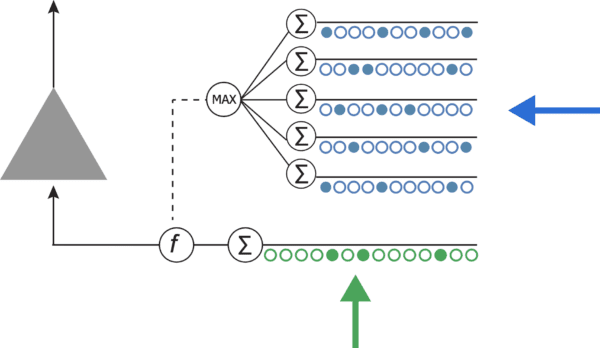
The k-Winner-Take-All function sparsified representations by picking out just 5% of all neurons in any single layer to fire. Putting these components together, we hoped to activate subnetworks of neurons based on different inputs to dendritic segments. This way, the backpropagation algorithm would only modify the connections of neurons in each subnetwork while leaving the rest of the connections in the entire network untouched. The figure below illustrates how different inputs received by dendritic segments would invoke separate subnetworks to learn and specialize in different tasks.
How did we fare? We tested our augmented network on the permutedMNIST benchmark, a standard benchmark in continual learning. Each task consists of classifying handwritten digits 0–9 but with a pixel-wise permutation applied to all images (the permutation is random and unique for each task). As shown below, our neural network augmented with (artificial) active dendrites and sparse representations can learn up to 100 tasks in sequence and retain at least 80% accuracy while standard neural networks fall to less than 50% accuracy on as many tasks!
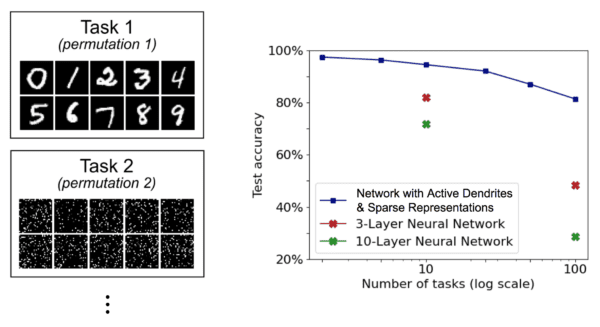 An illustration of permutedMNIST (left) adapted from van de Ven et al. (2019).
An illustration of permutedMNIST (left) adapted from van de Ven et al. (2019).
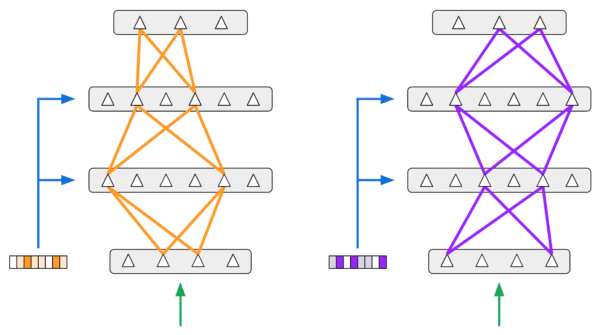
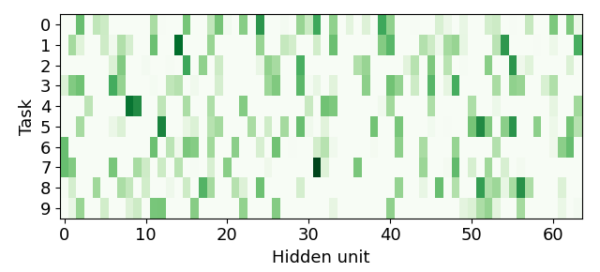
Furthermore, our analysis indicates that our network does indeed invoke separate subsets of neurons to learn different tasks. In the diagram below, each row shows which neurons in one of the intermediate layers of our network fired when evaluating the entire network on images from different tasks. As can be seen, different tasks invoke very different sets of neurons.
Note that our preprint includes many more details, including comparisons to other techniques, which we don’t discuss in this blog post.
Summary
In this blog post, we have highlighted the importance of learning continually, why neural networks fail to do so, and an initial attempt to enhance their knowledge retention by incorporating biological principles. Most of the neurons in a neural network today fire during a forward pass, and the backpropagation algorithm tweaks most connections when learning occurs. In effect, previously-acquired knowledge is gradually erased over time. The brain is unlike neural networks in that 1) only a tiny amount of neurons fire simultaneously and 2) learning only affects a sparse subset of connections. The principles behind active dendrites and sparse representations applied to neural networks can give rise to sparse subnetworks that specialize in learning specific tasks without affecting other subnetworks trained on different tasks, and this significantly improves continual learning capabilities.
As we strive to build systems that exhibit human intelligence, there’s still a large gap between the settings in which humans operate robustly and those which machines can handle. At present neural networks are capable of remarkable accuracy at a single task—but a single task only. Creating intelligent machines will require mastering a repertoire of skills, each utilized at different times and under varying conditions. This can be as simple as remembering how to get home after a few hours spent grasping the basics of quantum mechanics, or realizing that seeing a lion while hiking in the jungle means you should run for your life. A human that repeatedly forgets past experiences would be in big trouble. We must solve the continual learning problem before machines can truly become intelligent.
Read our preprint here: Going Beyond the Point Neuron: Active Dendrites and Sparse Representations for Continual Learning