
Developing AI-powered games on existing CPU infrastructures without breaking the bank
AI is opening a new frontier for gaming, enabling more immersive and interactive experiences than ever before. NuPIC enables game studios and developers to leverage these AI technologies on existing CPU infrastructure as they embark on building new AI-powered games.

20x inference acceleration for long sequence length tasks on Intel Xeon Max Series CPUs
Numenta technologies running on the Intel 4th Gen Xeon Max Series CPU enables unparalleled performance speedups for longer sequence length tasks.

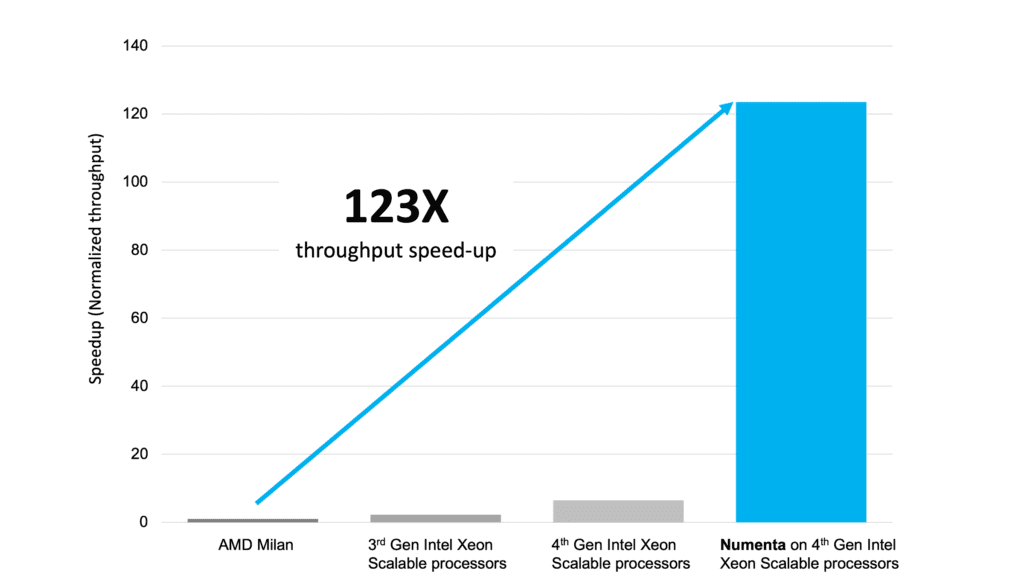
Numenta + Intel achieve 123x inference performance improvement for BERT Transformers
Numenta technologies combined with the new Advanced Matrix Extensions (Intel AMX) in the 4th Gen Intel Xeon Scalable processors yield breakthrough results.