
If you’ve watched our research meetings for the past few weeks, you may see a fresh face or hear a new voice on our videos. That is the face and voice of a PhD student Niels Leadholm, who spent 12 weeks with Numenta as a visiting research scholar. As one of Numenta’s first “virtual” interns, I asked Niels to share his work and experience interning at Numenta.
Q1: Hi Niels, can you tell us a bit about yourself and your area of research and expertise?
Sure! I’m a PhD student at the Oxford Lab for Theoretical Neuroscience and Artificial Intelligence. My interest is in understanding primate vision at a computational level, and using this understanding to improve artificial systems. Our lab looks at what is known about how our brains process visual information at both a high level (think psychology) and a low level (think neuroscience), and how this could inform improvements to machine learning approaches. My original background was actually as a medical doctor, but my passion for AI led me down online courses in mathematics and machine learning, and here I am today! One of my main focuses is on why engineered systems are vulnerable to what are known as adversarial examples – these are images that have been altered by small amounts of targeted noise (often so little that it’s imperceptible to a human), but a machine vision system becomes confident that the new image is something totally different. It’s hard to explain because it’s so counterintuitive to our own notion of recognising an object – you look at these and think, how could a system that is capable of classifying difficult images of tea cups and chihuahuas possibly think a school bus is an ostrich?
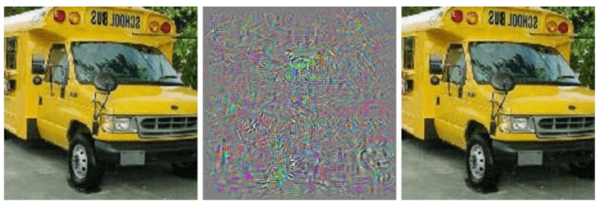
Q2: Why did you choose this particular topic to research?
Systems based on neural networks, such as convolutional neural networks, have revolutionized machine learning, taking on major challenges in the field. They also have certain resemblances to the computations performed in our own brain, which has led some scientists to use them as models of how humans solve tasks such as object recognition. The existence of adversarial examples makes it clear however that there are still some key differences in how our brain and these systems process images. I think it is a fascinating question to try to resolve what this difference is (or likely differences), because it would bring us closer to understanding our own brains, as well as enable us to engineer more powerful systems that align more closely with how we see the world.
Q3: Why did you decide to spend time at Numenta? How does your research relate to Numenta’s work?
Like everyone at Numenta, I’m very interested in the intersection of neuroscience and artificial intelligence, so at a general level, I knew it would be a great place to be. More specifically though, I was really interested in some of the recent work that Numenta has published on using grid cells to support object recognition. Given my interest in vision, I was interested to see if these ideas could be extended to images.
Q4: Can you share any research you’ve worked on during your internship here. What were the results?
I was looking at extending the ideas from the above paper to vision. The idea is that certain cells in our brain, called grid cells, can enable us to represent where in space our eyes are directed. As you move your eyes, your brain collects information about the world, and having a sensible concept of space – which grid cells can provide – would be crucial to integrating all of this information together. Take an image like the one below, and assume that you can’t see everything at once (i.e. you have to sequentially sample parts of the image), as would be the case in a real environment when your eyes move around. If you think about current systems, they would generally be trained to pass over the image, scanning line by line from the top. Of course, if you are trying to notice the tiger and avoid getting eaten, this isn’t a particularly great approach – it will take you far too long to see the predator! You might therefore try to take samples from the image at more informative locations and in an arbitrary order, but these systems stumble at integrating all of this together, even though this is something that our own brain does effortlessly. Numenta’s recent work presented a possible solution to this problem, and my research was focused on implementing a solution that actually worked on images (albeit pictures of hand-written digits, rather than tigers).

Q5: I understand you recently submitted a paper on work from your PhD. Can you describe what it was about, at a high level*?
I mentioned adversarial examples earlier. One idea I’ve explored for why they are possible is related to how objects and the features that form them are represented in our brain vs. artificial systems. If you look at the diagram below, Picasso does an excellent job of showing how our brain recognises an object with his “Bull” lithographs – as an image travels through our brain, we extract increasingly complex features from edges to object parts like eyes and horns, until we finally reach object concepts like ‘bull’. Artificial systems do this quite well, but unlike our brain, they also lose a lot of this information along the way, whereas when we look at an image of a bull, we see all of this and how it hangs together. In a sense, machine learning systems are seeing the forest but not the trees – and yet the trees still influence the decisions they make, which may be part of the reason they can be tripped up so easily. By adding representations similar to the ones we believe to exist in the primate brain, I’ve been creating artificial systems that capture this lost information and are therefore harder to fool.
*There are more technical details at the end of the post for anyone who is interested.

Q6: This was a rather unusual internship since you had to do it remotely due to the COVID-19 pandemic. How was your experience as a virtual visiting scholar?
Honestly, it’s been an amazing experience – of course I have no idea what it would have been like had I done it in person, but the whole team has been incredibly welcoming and supportive. The biggest hurdle was my internet connection sometimes being unstable, but I resolved this by sitting as close to my router as possible during presentations – not the worst challenge to overcome!
Q7: How will your time at Numenta shape your future work?
It’s been a very different way of thinking about how vision works (focusing on how it works at a serial level, that is part-by-part, rather than at a parallel level, that is all at once). It’s a complementary view – the two can work together – but I look forward to thinking more about how this is relevant to my PhD research.
Q8: What advice do you have for anyone who is interested in applying to Numenta’s Visiting Scholar Program?
If you’re like me then you won’t be an expert on Numenta’s various algorithms when you apply (and I still have a lot to learn now) but it definitely makes a difference if you’ve not only familiarized yourself with Numenta’s previous work, but also thought about what the next steps in the research are, and how your own background or research interests might be relevant to realising these.
Q9: What’s next for the research you did at Numenta?
Our plan is to put this together for an early pre-print paper, so this should be coming soon, and will offer more details. Eventually we’d like to extend it to more challenging tasks, and show how the approach can be useful to an agent that can interact with and respond to its environment.
Q10: Where can people follow this work?
You can follow me on Twitter (@neuro_AI), and otherwise the above work should be appearing in journals and conferences soon. In the meantime, you can watch a summary of the Numenta work on YouTube here, and my PhD work here.
Q11: Can you describe your recent work at Numenta for more technical readers?
Of course! Here is a technical summary of our findings:
Grid cells enable the brain to model the physical space of the world and navigate effectively via path integration by updating global self-position using self-movement. Recent proposals suggest that the brain uses similar mechanisms to understand the structure of objects in diverse sensory modalities, including vision. In machine vision, visual object recognition given a sequence of sensory samples of an image, such as saccades, is a challenging problem when the sequence does not follow a consistent, fixed pattern – yet this is something humans do naturally and effortlessly. We explored how grid cell-based path integration in a cortical network can reliably recognize objects given an arbitrary sequence of inputs.
Our network (GridCellNet) uses grid cell computations to integrate visual information and make predictions based on upcoming movements. We used local Hebbian plasticity rules to learn rapidly from a handful of examples (few-shot learning), and considered the task of recognizing MNIST digits given only a sequence of image feature patches. We compared GridCellNet to k-Nearest Neighbour classifiers as well as recurrent neural networks (RNNs), both of which lack explicit mechanisms for handling arbitrary sequences of input samples. We showed that GridCellNet can reliably perform classification, and generalize to both unseen examples and completely novel sequence trajectories. We further showed that inference is often successful after sampling a fraction of the input space, enabling the predictive network to quickly reconstruct the rest of the image given just a few movements. We proposed that dynamically moving agents with active sensors can use grid cell representations for efficient recognition and prediction, as well as navigation.
Q12: Can you describe the recent paper submission from your thesis research for more technical readers?
Yes definitely. In this work, we approached the issue of robust machine vision by presenting a novel deep-learning architecture, inspired by work in theoretical neuroscience on how the primate brain performs visual ‘feature binding’. Feature binding describes how separately represented features are encoded in a relationally meaningful way, such as a small edge composing part of the larger contour of an object, or the ear of a cat forming part of its head representation. We proposed that the absence of such representations from current models such as convolutional neural networks might partly explain their vulnerability to small, often humanly-imperceptible changes to images known as adversarial examples. It has been proposed that adversarial examples are a result of ‘off-manifold’ perturbations of images, as the decision boundary is often unpredictable in these directions. Our novel architecture was designed to capture hierarchical feature binding, providing representations in these otherwise vulnerable directions. Having introduced these representations into convolutional neural networks, we provided empirical evidence of enhanced robustness against a broad range of L0, L2 and L-infinity attacks in both the black-box and white-box setting on MNIST, Fashion-MNIST, and CIFAR-10. We further provided evidence, through the controlled manipulation of a key hyperparameter, synthetic data-sets, and ablation analyses, that this robustness is dependent on the introduction of the hierarchical binding representations.
Our Visiting Scholar Program is designed to promote collaboration, exchange ideas and allow participants to play an active part in our research meetings while continuing their normal research. If you’re interested in applying for the Visiting Scholar Program, click here to apply.