
Science advances faster when researchers can verify each other’s results. However, this is easier said than done, as evident by the long-standing issue about reproducibility of scientific research. This widespread “reproducibility crisis” has been featured in newspapers, magazines, education-related publications, and scientific journals. According to a survey conducted by Nature, over 70% of 1,576 researchers from various disciplines have tried and failed to reproduce another scientist’s experiments. And according to a report published in Science, an effort to successfully replicate 100 experiments published in prestigious journals was met with only 39 successful attempts.
The issue of reproducibility is a challenge that we also face. If you’ve ever read our papers and attempted to run our experiments, you may have had difficulty searching through our GitHub repositories and figuring out which part of the code was used for each paper. Sometimes people even come to us saying that they couldn’t get our experiments to work. Because research is fluid and constantly moving forward, our code can get outdated quickly. This is problematic for those who want to see and replicate the results for themselves.
We have been producing more manuscripts and peer-reviewed papers over the past couple of years, and in keeping with Numenta’s open science / open research philosophy, we felt it was important to address this problem. We wanted to improve the transparency in what we publish by making the code from our research papers easy to find and easy to reproduce. Our hope was that doing so would encourage more people to engage with our research, tweak our experiments, and provide feedback.
This is why we decided to create a new place to share our data in a more straightforward and organized manner– a project I recently undertook. To do so, I needed to sort through our research repositories, cull through the ones related to a specific paper, pull them out, freeze them in time, and arrange them in a way that’s easy for anyone outside of Numenta to find. I thought of this project as a standardized guide for those who want to use our technology. Let me walk you through it.
If you go to our new repository, you will see that it is now organized by publications and by the names of the papers.
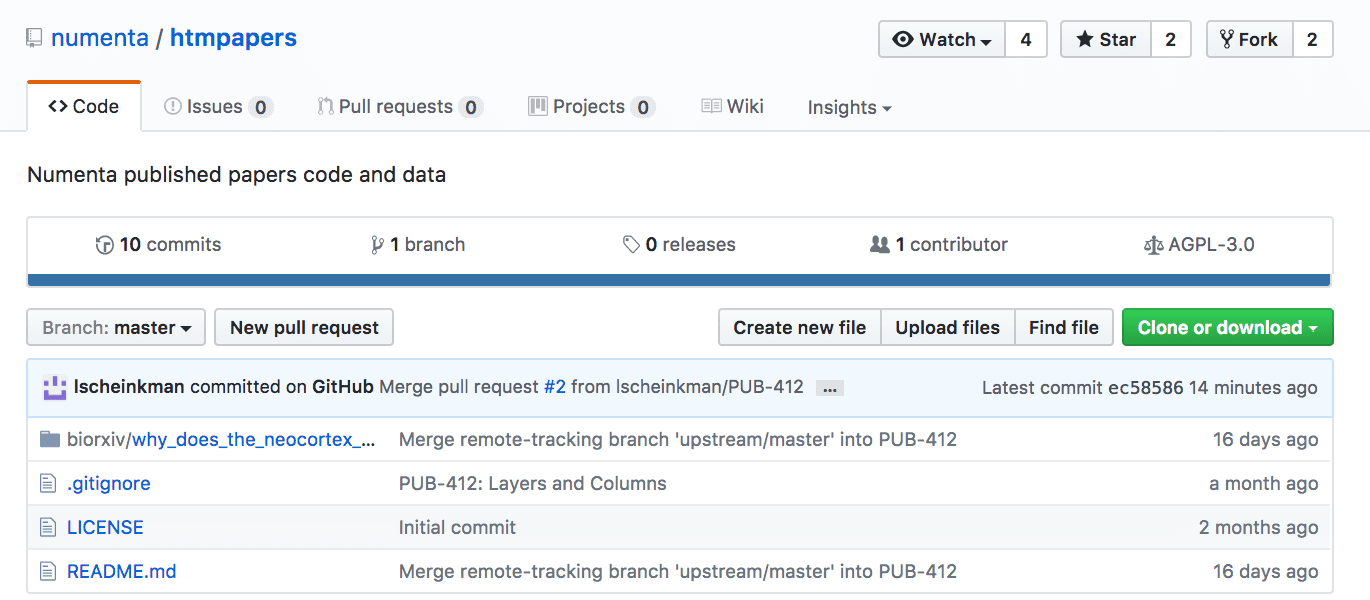
Let’s say that you are looking for the code used in the experiments on our Why Does the Neocortex have Layers and Columns paper from bioRxiv.
You can either:
- Click bioRxiv/why_does the_neocortex_have_layers_and_columns, or
- Scroll down and click on “Sources” under the description of the paper.
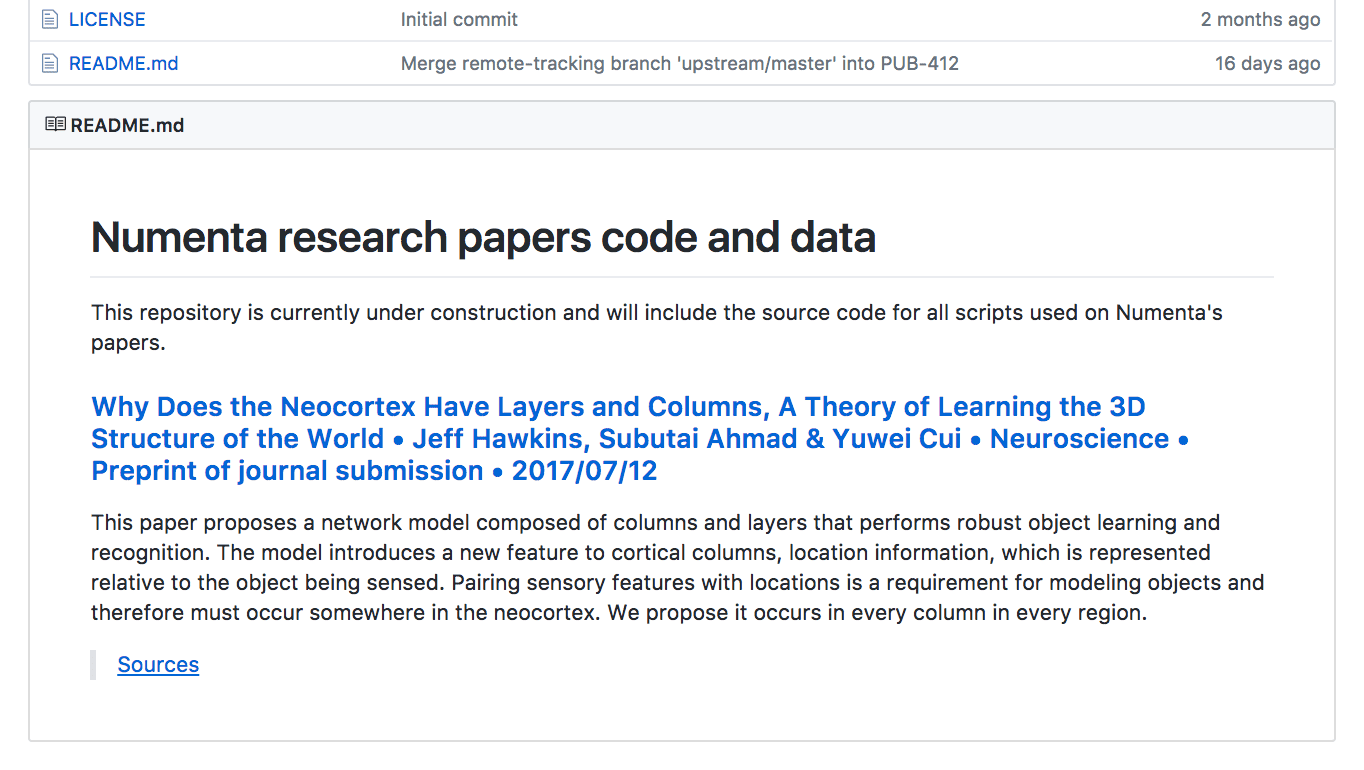
Each folder has a README.md file. In it, there are instructions on how to install the requirements, how to generate figures, and explanations of all the figures in the paper.
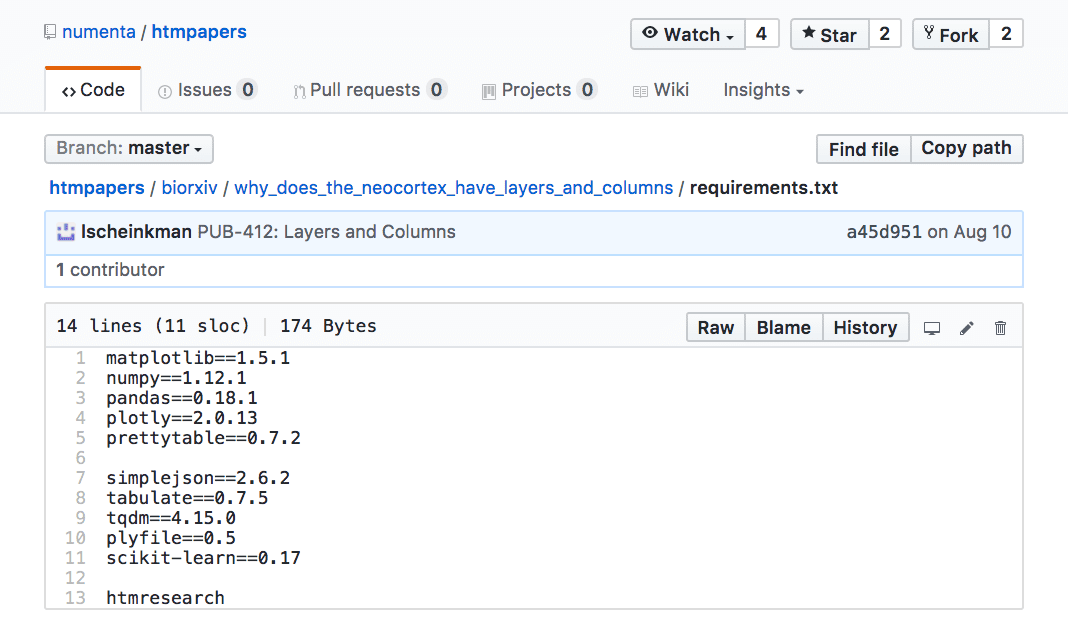
There is also a requirements.txt file which tells you the software and software versions we used to run the experiments. I have frozen the repositories in time, so that you can replicate our results from the time when the papers were written.
For now, we have only done this for one recent paper– Why Does the Neocortex have Layers and Columns. It is still a work in progress and should be considered “beta”. We will be updating the repository to include our other papers in the weeks to come.
I hope you find this useful, and we welcome you to experiment with our code. If you do, we would be happy to see your results. We also welcome feedback about this new repository. If you have any comments or suggestions, please don’t hesitate to let us know.
Happy Experimenting!